Recommendation systems

Internet
is flooded with information every day. Easy access to large amount of
information along with difficulty in judging the validity of so much content
can lead to information overload. As
a result, e-commerce applications and social media sites are increasingly
challenged to attract new users and retain existing ones. Based on user
interests and preferences, these systems recommend items that may be of
interest or value to the customers/users.
Recommendation systems help users deal with the information-overload by giving them recommendations of products, etc.They help businesses make more profits, i.e., selling more products.
Recommendation systems help users deal with the information-overload by giving them recommendations of products, etc.They help businesses make more profits, i.e., selling more products.
Recommendation
systems are a type of information filtering system that uses the
preferences of a group of people to make recommendations to other people. Some
of the well-known features of recommendation system are: product recommendation for
online shopping, social matching, targeted content/advertising etc.
35%
of product sales in Amazon result from recommendations. Recommendations
generate 38% greater click through in Google News. Two third of movies rented
in Netflix were recommended.

Collaborative Filtering is that user will be recommended items what his friends or users similar to him have preferred. Two types User base and item based. Content based is recommend items to user based what he himself have preferred in the past.
Hybrid is a combination of the above two.
Lets
focus on Collaborative filtering for now. Steps 1) Collecting preferences,
Similarity scoring , Ranking and Making recommendations..

There
are many different approaches of CI today, Collaborative filtering, Content
based and hybrid approach. Collaborative Filtering is that user will be recommended
items what his friends or users similar to him have preferred. Two types User
base and item based. Content based is recommend items to user based what he himself have
preferred in
the past. Hybrid is a combination of the above two.
Lets
focus on Collaborative filtering for now. Steps 1) Collecting preferences,
Similarity scoring , Ranking and Making recommendations..

Collaborative Filtering
Cosine (Vector) similarity
Items and their ratings are represented as vectors. The similarity is the angle between these vectors:
Pearson (correlation) similarity
For a given set of items, the similarity is based on the difference in the rating by common users from average ratings for those items: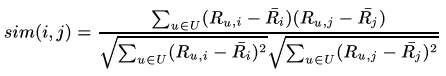
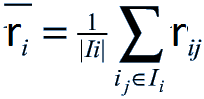
Ii is the set of items on which user i voted; rij corresponds to the vote of user i for item j
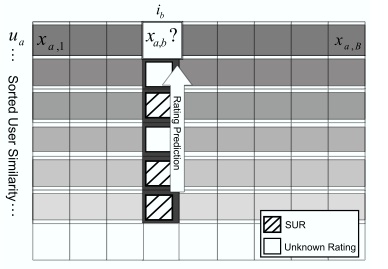
Rating prediction:
wa,u is the similarity between ua and uu.
 W(k, j) is a cosine similarity for the item
W(k, j) is a cosine similarity for the item
Measures the rating by the user i for all m items, averaged by their similarity to the predicted item
Collaborative
filtering is a method of making automatic predictions for a user by
collecting preference information from large group of people and finding
a smaller set with tastes similar to the user.
The workflow of a collaborative filtering system is:
- Collecting user preferences/rating of items.
- Finding similar users by matching the user’s ratings against other users ratings for an item.
- Ranking users who have similar preferences based on the similarity score
- Recommend items that the similar users have high preference for but not yet being rated by this user (assuming the item is not familiar to this user since the user did not rate it).
Methodology
Collaborative filtering is of two types: (i) User-based and (ii) Item-based
User-based collaborative filtering
Identify
people who share similar rating patterns as the user and use the
ratings from these like-minded users to calculate a prediction for the
active user. For instance, if a person A and person B like a product, A
is more likely to buy a different product that B purchased than to buy a
product that a randomly chosen person purchased.
User-based Nearest Neighbor algorithm applies this principle.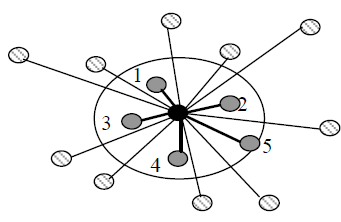
The
distance between the target user and every other user is calculated and
the closest k (k is 5 in this case) users are chosen as ‘neighbors’.Item-based collaborative filtering
This
filtering proceeds in an item-centric manner (users who bought x also
bought y). An item-item matrix is built to determine relationships
between pairs of items. The prediction for preference for an item is
made using this matrix and the user’s data.
Slope One algorithm applies this principle.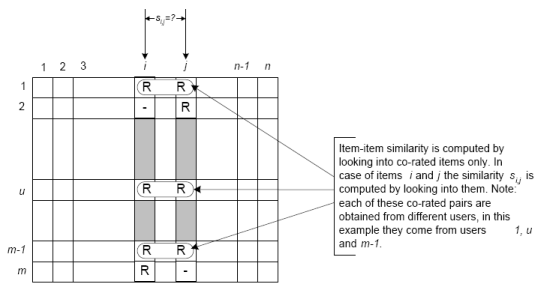
Collaborative filtering based on observations of user behavior
The
data collected through user actions (clicks, page-view time, purchases,
tagging, and page navigation) play a significant role in the prediction
process. The predictions made have to be filtered through application
logic to handle system response to such actions to boost purchase. A/B
testing can be used effectively to learn about people.
Similarity measures
Some of the mathematical formulae used to calculate the similarity between two items:
Cosine (Vector) similarity
Items and their ratings are represented as vectors. The similarity is the angle between these vectors:
Pearson (correlation) similarity
For a given set of items, the similarity is based on the difference in the rating by common users from average ratings for those items:
User based nearest neighbor algorithms
Find the similarity between each user and the active user. Select the ‘neighbors’ to use for recommendations.
The mean vote for user i: Ii is the set of items on which user i voted; rij corresponds to the vote of user i for item j
Rating prediction:
wa,u is the similarity between ua and uu.
Item based nearest neighbor algorithms
The prediction is based on the user’s ratings for similar items W(k, j) is a cosine similarity for the itemMeasures the rating by the user i for all m items, averaged by their similarity to the predicted item
Challenges in Collaborative Filtering
- Calculating a user’s perfect neighborhood is expensive. Techniques like sampling, clustering can be employed for comparison against all other users.
- User-item matrix could be extremely large and sparse and hence can affect performance of the recommendation.
- New users need to rate sufficient items before the recommendation engine can predict for the user, since the recommendations are based on the user’s past performance (cold start problem).
- As the dataset grows, the algorithm could face scalability problems.
- The prevalence of synonyms is difficult to track and it degrades the performance of the algorithm.
To
reduce domain complexity, reduce the dimensionality of recommender
system databases to a smaller number of underlying dimensions. Popular
Dimensionality reduction algorithms: Singular value decomposition and
Principal Component Analysis. Highlights of this approach are: more
accurate predictions, better run-time performance and larger numbers of
co-rated dimensions.
Enhancing Collaborative filtering with Social relationships
Recommendation
from social relationships (as in social networking sites like Facebook,
LinkedIn) is more effective compared to traditional approach of
collaborative filtering. The user knows the people and can judge their
preference better than a random person with similar interests. Social
relationships could include friends, friends of friends, and other
people of interests.
Studies
have shown that friend-relationships provide similar ratings in taste
related domains. Cliques show a higher similarity than mere friend-pairs
on the average. Hence, cliques and friend pairs are suitable
recommendation sources as they share a common taste in the investigated
domain. Social recommendations are more transparent than traditional
collaborative filtering as the user will know why a certain
recommendation was made (based on preferences by user’s social network).
User
based Collaborative filtering
Generates
recommendation based on similar customers
Represent
customer as an N dimensional vector of items
Similarity
– cosine of the angle between the vectors
Computationally
expensive O(M)
Cluster
Classification
problem
Divide
customer base into segments
Assign
user to segment containing similar users
Computes
user’s similarity to vectors that summarize the segment
Better
online scalability but poor quality recommendations
Search based
Search
query based on user’s purchased items
- find other popular items with similar
keywords/subject
For
users with less items –performs well
For
users with more items – query too large ; impractical
- subset of query chosen; reduces quality
Item to Item Collaborative filtering
Matches
user’s purchased items to similar items
Builds
a similar items table – items that customers tend to purchase together
Vector
corresponds to item ; its dimensions correspond to customers
Offline
computation – time intensive – O(NM)
Online
computation – subsecond processing time – depends only on
items purchased by user

Recommend
personalized set of videos based on user’s recent actions in the site.
Ranking
of these recommendations is based on relevance, user personalization, video
quality and diversity.
Data:
(1) content data (video streams and its metadata) and (2) explicit &
implicit user activity data.
Explicit
activities are actions like subscribe, favorite, like. Implicit activities are
data generated as a result of users interacting with videos (e.g. duration of
watch).
As
a batch process, the recommendation system constructs the mapping of video v to
a set of similar/related videos as a graph. The mapping is computed by using
the technique known as association rule mining or co-visitation counts. For
each pair of videos (vi, vj) the
number of times they were co-watched within a given time period is counted.
The
relatedness score of video vj to base video vi is given by:
Where
cij is
the co-visitation count; f(vi, vj) is a normalization function that takes
the “global popularity” of both the seed and candidate videos into account and
is given by f(vi, vj) =
ci · cj. ci
and cj are
the total occurrence counts across all sessions for videos vi and vj
respectively.
The
videos can be seen as a directed graph over the set of related videos. For each
pair of videos (vi, vj),
there is an edge eij from
vi to vj iff vj Ri, with the weight of this edge given by
the above equation.
In
order to obtain candidate recommendations C for a given seed set S, expand it
along the edges of the related videos graph. Recommendation candidate C is
denoted as:
Where
Ri is
the related videos for each video vi. This set of candidate videos are ranked
based on video quality, user specificity and diversification.
A/B
testing can be used for evaluating the performance of the recommendation
system. The site traffic is separated into groups where one group acts as the
baseline and the other group is exposed to a new feature. The two groups are
then compared against one another. Metrics considered for evaluating
recommendation quality and performance: click through rate, session length,
time until first long watch.
Metrics
considered for evaluating recommendation: click through rate, session length,
time until first long watch.

Hybrid
approach of CB-CF was shown to perform better than CF alone.
An
accurate profile of users' current interests is critical for the success of
content-based recommendation systems.
Google
News employs hybrid of content-based and collaborative methods on the live
traffic in its site. Combining the content-based method and the collaborative
method offers the advantages of both methods and shows improved performance. An
accurate profile of users' current interests is critical for the success of
content-based recommendation systems. These systems can construct profiles
automatically from users' interaction with the system.
For
each article the system calculates:
(1)
content-based recommendation score CR(article) - based on the topic, users click history (to
capture user’s interests) and interest and news trend based on click behavior
from the general public and
(2)
collaborative filtering score, CF(article) - based on clustering dynamic
datasets (MinHash
based on the proportional overlap between the set of items they clicked)
Recommendation
candidates is given by: Rec(article) = CR(article)×CF(article)
Based
on the evaluation of live trial, hybrid approach of CB-CF was shown to perform
better than CF alone.

Content
Matching
Recommends
users associated with similar content. Creates a bag-of-words representation of each user (from user
profiles, status messages, tags).
Two
users will be considered similar if they share many common words in their
associated content.
The
weight of the similarity scores increases if only a few users share those
words.
Performance
is poor. Algorithm can be enhanced by matching content with social link
information derived from user’s social network structure.

Recommendation
from social relationships (as in social networking sites like Facebook,
LinkedIn) is more effective compared to traditional approach of collaborative
filtering. The user knows the people and can judge their preference better than
a random person with similar interests. Social relationships could include
friends, friends of friends, and other people of interests.
Studies
have shown that friend-relationships provide similar ratings in taste related
domains. Cliques show a higher similarity than mere friend-pairs on the
average. Hence, cliques and friend pairs are suitable recommendation sources as
they share a common taste in the investigated domain. Social recommendations
are more transparent than traditional collaborative filtering as the user will
know why a certain recommendation was made (based on preferences by user’s
social network).
The Cold Start Problem
The
recommendation system will not be able to draw inferences for users or
items without sufficient information, e.g. new users to a new site, new
items without tags. This is known as the Cold Start problem. A hybrid
approach of content-based matching and collaborative filtering is
adopted to reduce the effect of the problem.
New items are assigned a rating based on the ratings to other similar items according to the items' content-based characteristics.
The new user's
profile is updated automatically based on the user activities such as
click-through data, searches, browsing history, tagging, friends and
communities the user belongs to (implicit feedback).
For items without tags,
a hybrid with a content based recommender is employed and content based
tag extraction is used. Collaborative filtering is applied to enrich
tags. However this approach will not work for recently created users or
items.
REFERENCES
Programming
Collective Intelligence – Toby Segaran
J.
Davidson, B. Liebald, J.
Liu, P. Nandy
& T. Vleet
(2010). The YouTube Video Recommendation System. RecSys
'10 Proceedings of the fourth ACM conference on Recommender system.1-4. Doi:
10.1145/1864708.1864770
J.
Liu, P. Dolan & E. Pedersen (2010). Personalized news recommendation based
on click behavior. IUI '10: Proceedings of the 15th
international conference on Intelligent user interfaces. Doi:
10.1145/1719970.1719976
A.
Das, M. Data, A. Garg
& S. Rajaram (May
2007). Google News Personalization
Scalable Online Collaborative Filtering. WWW '07: Proceedings of the 16th
international conference on World Wide Web. Doi: 10.1145/1242572.1242610
Greg
Linden, Brent Smith, and Jeremy York Amazon.com Industry
Report
Recommendations Item-to-Item Collaborative
Filtering
Hybrid Recommender Systems: Survey and Experiments - Robin Burke, California State University, Fullerton, Department of Information Systems and Decision Sciences
The YouTube Video Recommendation System - James Davidson, Benjamin Liebald, Junning Liu, Palash Nandy, Taylor Van Vleet, Google Inc
Google News Personalization: Scalable Online Collaborative Filtering - Abhinandan Das, Mayur Data, Ashutosh Garg, Shyam Rajaram, Google Inc
Recommendations in Taste Related Domains: Collaborative Filtering vs. Social Filtering, Georg Groh, Christian Ehmig, TU München, Department of Informatics
DoYou Know? Recommending People to Invite into Your Social Network - Ido Guy*, Inbal Ronen*, Eric Wilcox** - *IBM Haifa Research Lab, ** IBM Almaden Research Center
“Make New Friends, but Keep the Old” – Recommending People on Social Networking Sites - Jilin Chen*, Werner Geyer**, Casey Dugan**, Michael Muller**, Ido Guy*** - *University of Minnesota, **IBM T.J Watson Research, ***IBM Haifa Research Lab
Hybrid Recommender Systems: Survey and Experiments - Robin Burke, California State University, Fullerton, Department of Information Systems and Decision Sciences
The YouTube Video Recommendation System - James Davidson, Benjamin Liebald, Junning Liu, Palash Nandy, Taylor Van Vleet, Google Inc
Google News Personalization: Scalable Online Collaborative Filtering - Abhinandan Das, Mayur Data, Ashutosh Garg, Shyam Rajaram, Google Inc
Recommendations in Taste Related Domains: Collaborative Filtering vs. Social Filtering, Georg Groh, Christian Ehmig, TU München, Department of Informatics
DoYou Know? Recommending People to Invite into Your Social Network - Ido Guy*, Inbal Ronen*, Eric Wilcox** - *IBM Haifa Research Lab, ** IBM Almaden Research Center
“Make New Friends, but Keep the Old” – Recommending People on Social Networking Sites - Jilin Chen*, Werner Geyer**, Casey Dugan**, Michael Muller**, Ido Guy*** - *University of Minnesota, **IBM T.J Watson Research, ***IBM Haifa Research Lab


Comments
Post a Comment